机器学习最具有理论计算的部分,有点难
the Support Vector Machine (SVM)
监督学习算法
也称大间距分类器,因其设置了一个安全区域
在某些情况下比逻辑回归更适合构造非线性复杂分类器

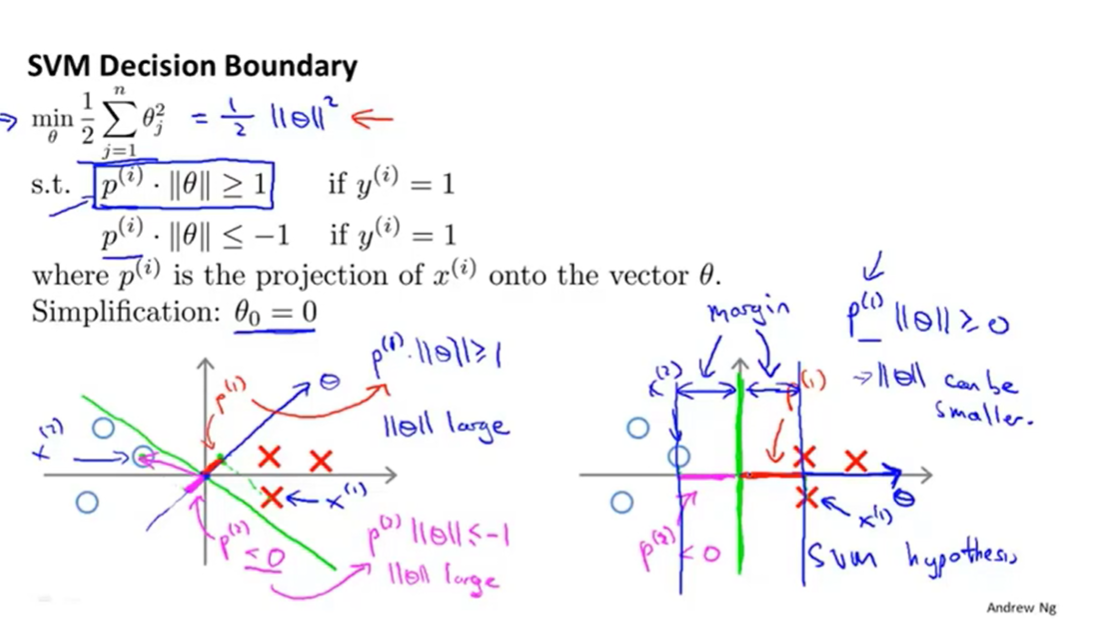
优化目标: 最小化假设函数,一样是找到最优的θ
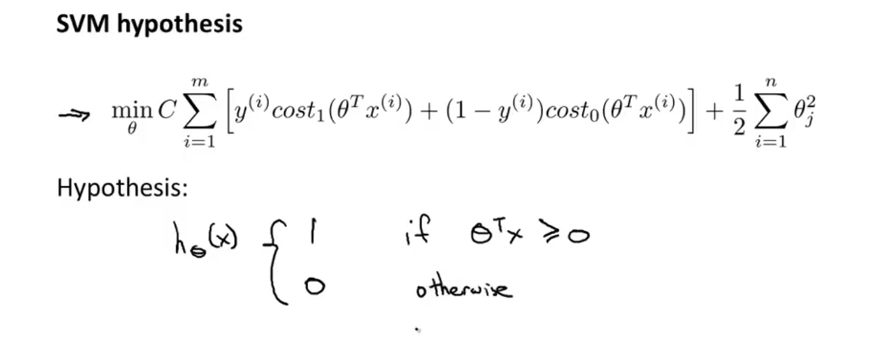
决策边界以最大的间距与训练集分开
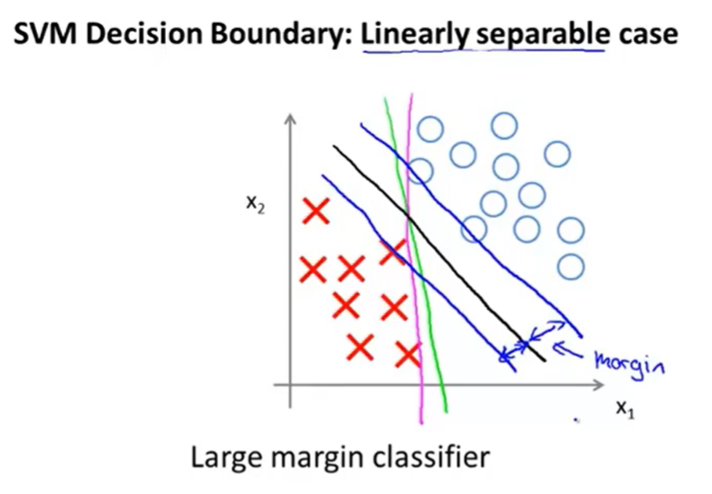
C过大 对异常点敏感 会导致训练集与边界线之间的间距变小。

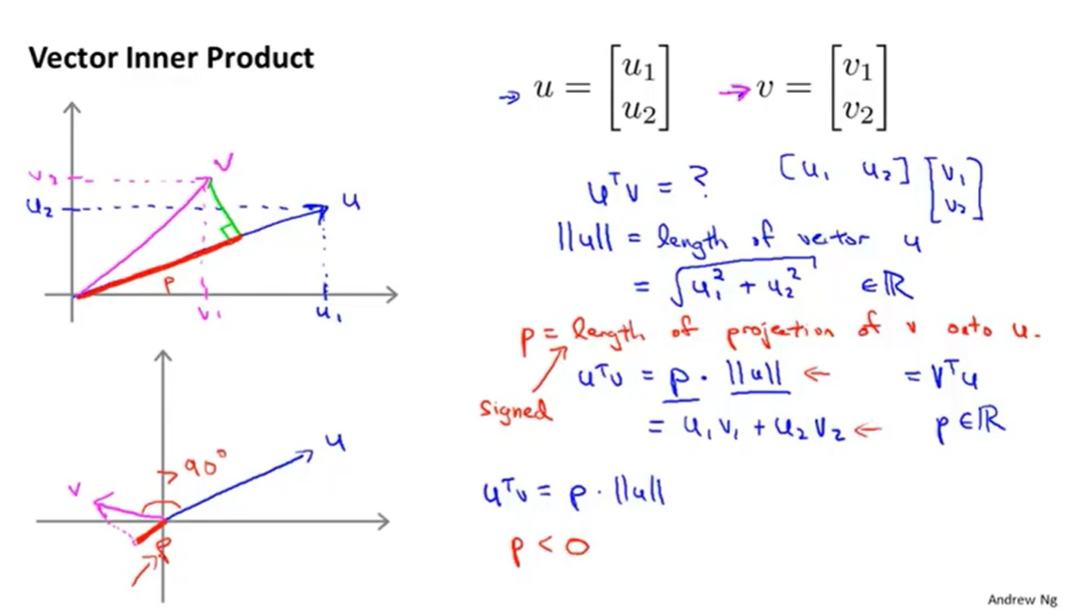
向量内积的性质
其中 P 是 投影,有符号的实数
|| u|| 向量u的欧几里长度 就是 我们所说的“向量长度”
运用于代价函数的计算
θ的方向与决策边界90°正交
θ_0代表决策边界与Y轴的截距
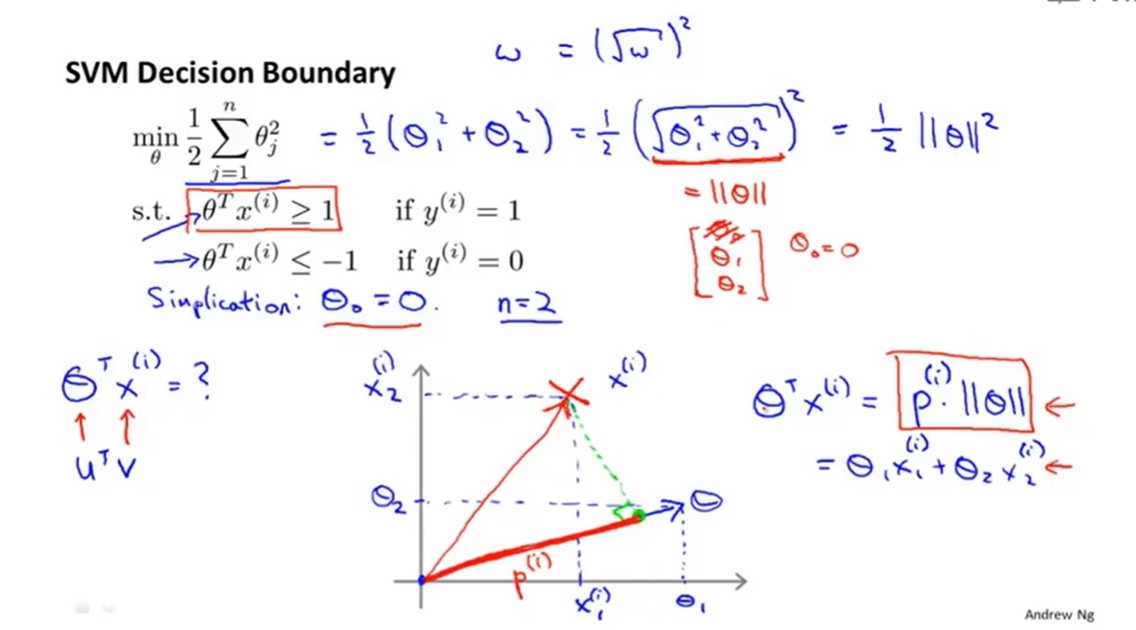
为什么支持向量机会找到最大间距呢?
如图它会使得P最大,从而min||θ||,P就是训练集在θ上面的投影,
在这样的过程中便找到了最大间距~
核函数
利用核函数K根据特征 X 和标记点 l 定义新的特征量 f
本质上 f是X与l的相似度

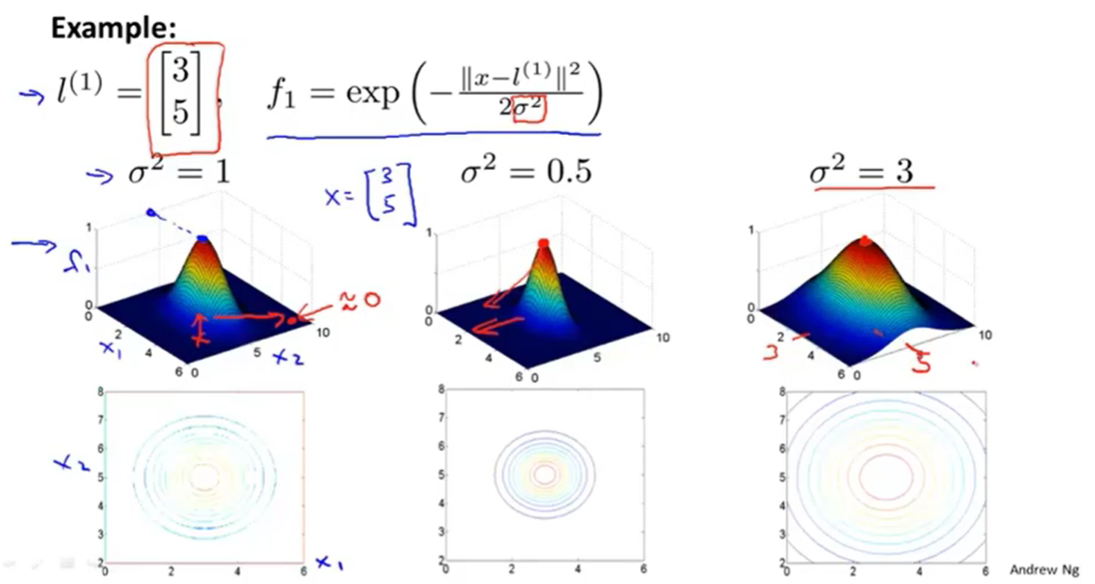
高斯核函数
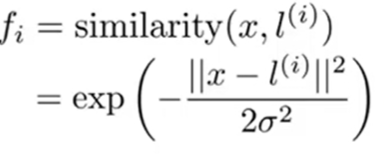
核函数与标记点共同定义复杂非线性决策边界
越大 特征量x从标记点l离开时变化速度越大
同样不需要正则化θ_0
θT M θ 更多的是为了计算效率,稍微改变了正则化的结果

参数的选择
C过大 相当于逻辑回归中 λ过小,不正则化 ,易出现过拟合;反之易出现欠拟合。
σ^2 过大 f变化过于平滑,易出现欠拟合;反之f变化剧烈易出现过拟合。

实现步骤
n表示特征量的数量,m表示训练集的数量
可以在n X多 ,m少的情况 不要核函数,得到一条线性决策边界
可以在m X多 ,n少的情况 选择高斯核函数,得到一条复杂非线性决策边界

在进行高斯核函数前不用特征归一化


多类别分类
类似于 逻辑回归中的“一对多” ,选择概率最大的 z

tips:
逻辑回归与不带核函数的支持向量机十分类似,效果略有不同。
神经网络适合大部分问题,但速度可能被限制

编程作业
gaussianKernel.m
1 | function sim = gaussianKernel(x1, x2, sigma) |
dataset3Params.m
1 | function [C, sigma] = dataset3Params(X, y, Xval, yval) |
processEmail.m
1 | function word_indices = processEmail(email_contents) |
emailFeatures.m
1 | function x = emailFeatures(word_indices) |