原因
适应于非线性假设
sigmoid(logistic)activation function : 激活函数 指代 g(z)
X_0 偏置单元,值永远是1
θ 代表 参数或权重
架构
输入层-》隐藏层(不止一个)-》输出层
符号:
a(i)_j表示 第i层,第j个神经元或单元的激活项(由具体的神经元计算并输出的值)
θ(i) 表示 从第i层到第i+1层之间映射的权重矩阵
偏置单元省略没有写。
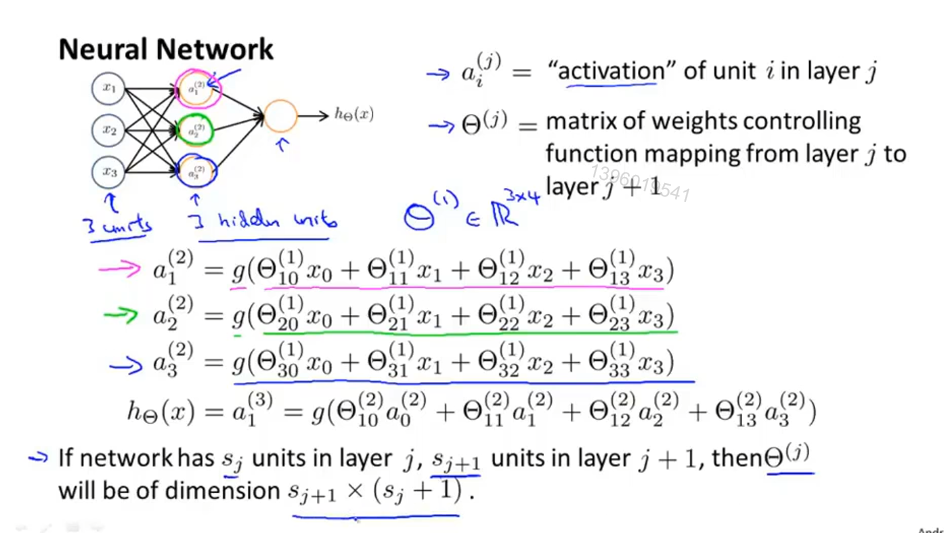
如果第 j 层中有 S_j 个单元,第 j+1 层中有 S_j+1 个单元,则θ(j)的维数: S_j+1*( S_j + 1)
前向传播(向量化)
依次计算激活项,从输入项到输出项的过程。
下面是它的向量化实现
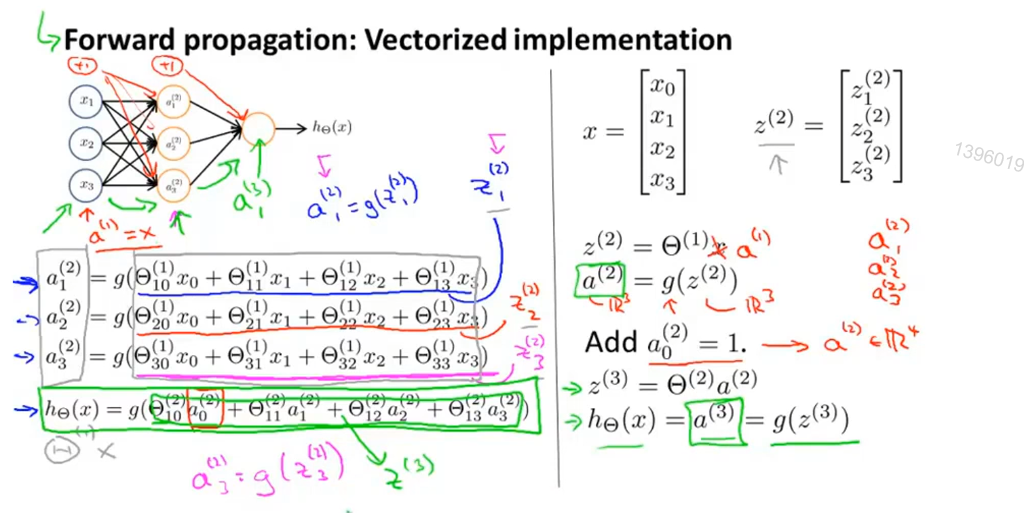
最后一层隐藏层到输出层 类似于 逻辑回归
多类别分类(一对多分类的扩展)
编程作业
displayData.m
1 | function [h, display_array] = displayData(X, example_width) |
lrCostFunction.m
1 | function [J, grad] = lrCostFunction(theta, X, y, lambda) |
oneVsAll.m
1 | function [all_theta] = oneVsAll(X, y, num_labels, lambda) |
predict.m
1 | function p = predict(Theta1, Theta2, X) |
predictOneVsAll.m
1 | function p = predictOneVsAll(all_theta, X) |
sigmoid.m
1 | function g = sigmoid(z) |