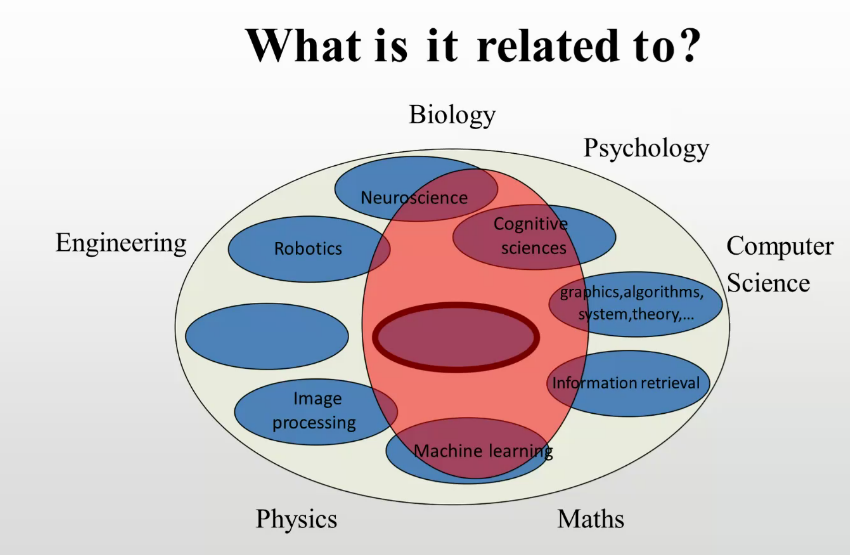
定义
计算机利用相机和计算能力来感知现实世界
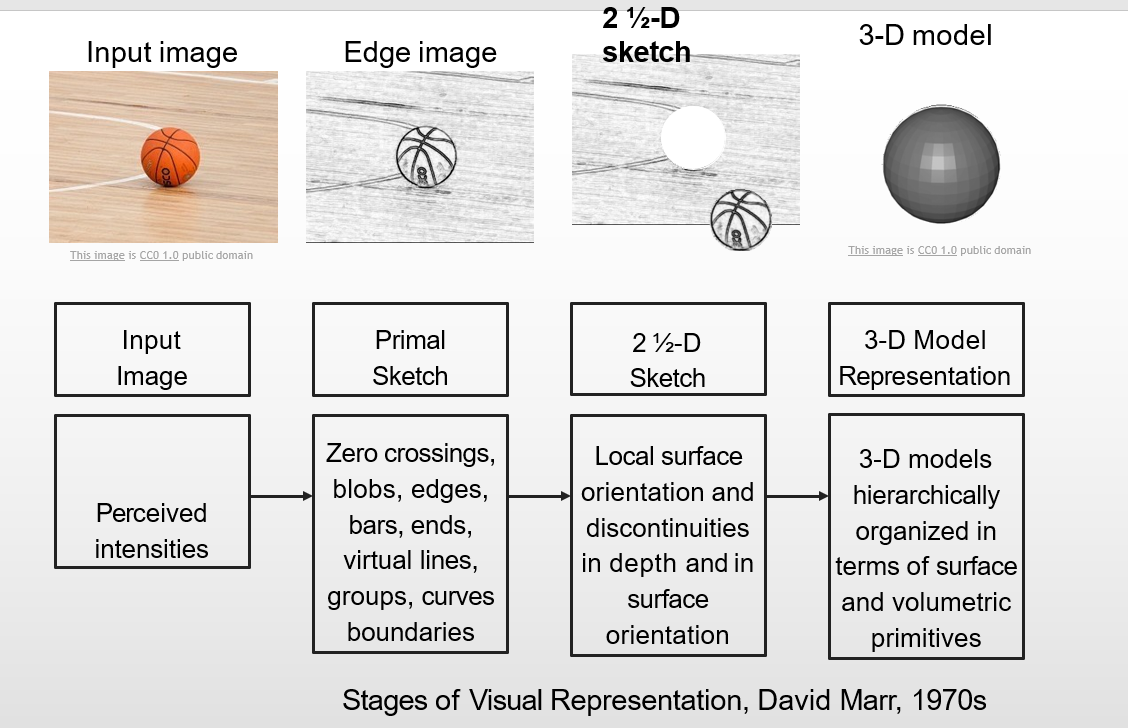
2.5维:在平面上浮凸出来的一个空间,可以想象是浮雕所处于的一种空间(伪3D)
2.5维:在平面上浮凸出来的一个空间,可以想象是浮雕所处于的一种空间(伪3D)
2.5D是从一个视角去看的,像素之间没有距离的概念,3D是从多视角去看的,有距离的概念
实现方案
传统算法
HOG、金字塔、SIFT
神经网络
CNN
数据集
IMAGENET(李飞飞团队)https://v.qq.com/x/page/z0399f36dv1.html有关介绍
分类
几何视觉(3D\2D)
语义识别(分类、检测、提取)

基础
图像的采样与量化
如何训练神经网络
关键
Activation Functions
Data Preprocessing
Weight Initialization
Batch Normalization
Babysitting the Learning Process
Hyperparameter Optimization
optimization
Regularization
Transfer Learning
环境
CPU vs GPU
Deep Learning Frameworks
Caffe / Caffe2
Theano / TensorFlow
Torch / PyTorch
TensorFlow is a safe bet for most projects. Not perfect but has huge community, wide usage. Maybe pair with high-level wrapper (Keras, Sonnet, etc)
I think PyTorch is best for research. However still new, there can be rough patches.
Use TensorFlow for one graph over many machines
Consider Caffe, Caffe2, or TensorFlow for production deployment Consider TensorFlow or Caffe2 for mobile
激活函数
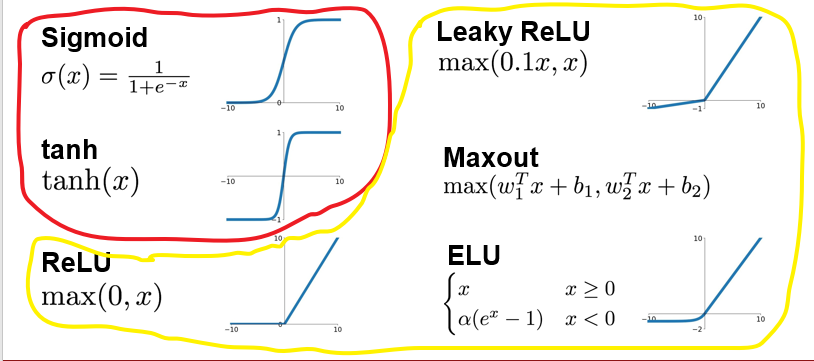
红色区域存在饱和(f(x)*f`(x)=0)神经元,黄色区域均为非饱和神经元
sigmoid激活函数
1.饱和神经元将会使得梯度消失
2.Sigmoid输出不是以零为中心的
3.exp() is a bit compute expensive
由于使用sigmoid激活函数会造成神经网络的梯度消失和梯度爆炸问题,所以许多人提出了一些改进的激活函数,如:用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。
tanh(x)激活函数
1.值均在[-1,1]之间
2.以零为中心点(这点很优秀)
3.仍然会在饱和时使得梯度消失
ReLU激活函数
1.非饱和(在正区域)
2.非常计算效率
3.在实践中,收敛速度比sigmoid/tanh快得多(例如6x)
4.实际上比sigmoid更合理
但是不是以零为中心点,并且容易出现死亡神经元
Leaky-ReLU激活函数
1.不饱和
2.计算效率高
3.在实践中比sigmoid/tanh收敛得快得多!(例如6 x)
4.不存在死亡神经元
Parametric Rectifier (PReLU) f(x) = max(ax, x)
ELU激活函数
1.继承ReLU的所有好处
2.接近于零的平均输出
3.负饱和状态与Leaky-ReLU相比,对噪声有一定的鲁棒性
但是计算中需要exp(),意味着计算量较高
Maxout激活函数
1.没有点积的基本形式——>非线性?
2.泛化ReLU和Leaky-ReLU
3.线性!不饱和!没有死亡神经元!
实际使用
Use ReLU. Be careful with your learning rates
Try out Leaky ReLU / Maxout / ELU
Try out tanh but don’t expect much
Don’t use sigmoid
数据预处理
使用PCA和数据增强使得数据以0为中心
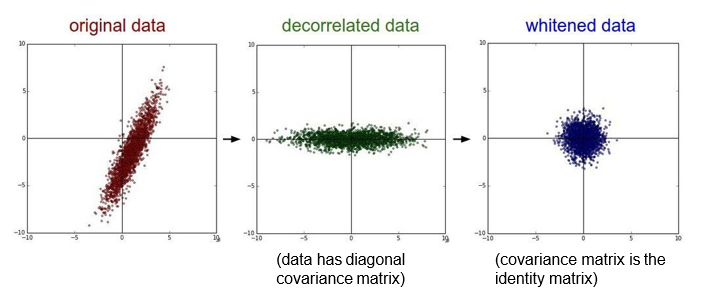
就是尽可能的让输入和输出服从相同的分布,这样就能够避免后面层的激活函数的输出值趋向于0
网络参数初始化
- 很小的随机数(在小型神经网络中表现可以,但在深层网络存在问题)
- 何凯明对ReLU的初始化方法
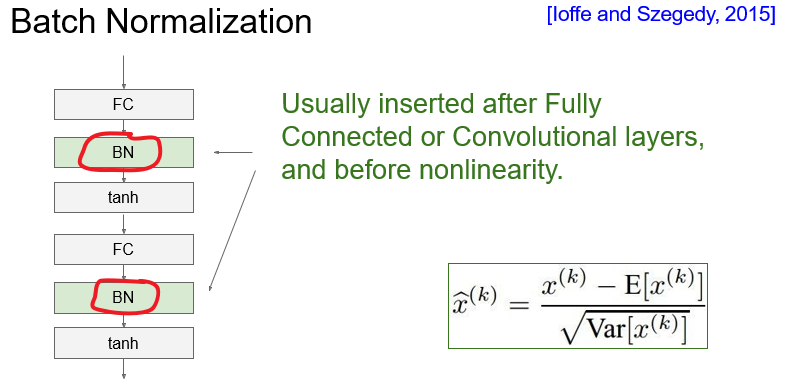
批归一化
位置:通常插入在全连接层或卷积层之后,在非线性之前。
作用:使得数据的分布更符合高斯或正态分布
开始训练
尝试输出每个epoch的损失值(是否下降、下降速率)、精准度
尝试学习率按(一定规律)衰减
找到合适的超参
(1)交叉验证集
(2)随机查找 or 网格查找(大概确定范围)
(3) 正则化
(4)可视化工具
梯度下降
随机梯度下降
小批量SGD 会有噪声
动量梯度下降

牛顿动量
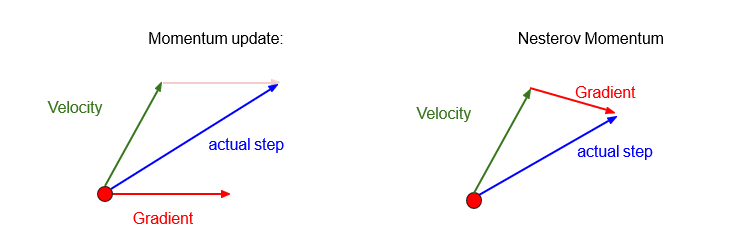

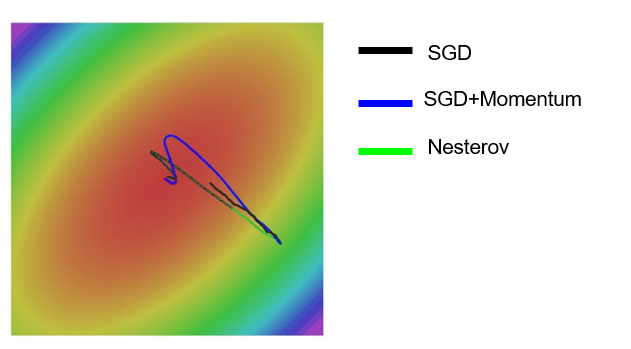
以下算法查看大佬解析深度学习优化算法解析(Momentum, RMSProp, Adam)
Adam适应性梯度算法
添加了基于每个维度的历史平方和的梯度元素的缩放
RMSProp
L-BFGS
- Usually works very well in full batch, deterministic mode
i.e. if you have a single, deterministic f(x) then L-BFGS will probably work very nicely
- Does not transfer very well to mini-batch setting. Gives bad results. Adapting L-BFGS to large-scale, stochastic setting is an active area of research.
实际使用
1.Adam is a good default choice in most cases
2.If you can afford to do full batch updates then try out
L-BFGS (and don’t forget to disable all sources of noise)
正则化
主因:数据链不够大 or 多样性不足
目的:提高模型泛化能力
1.给损失函数增加正则项
2.Dropout(随机删除)
总结
Activation Functions (use ReLU)
Data Preprocessing (images: subtract mean)
Weight Initialization (use Xavier init)
Batch Normalization (use)
Babysitting the Learning process
Hyperparameter Optimization
(random sample hyperparams, in log space when appropriate)
Optimization
- Momentum, RMSProp, Adam, etc
- Regularization
- Dropout, etc
-Transfer learning
-Use this for your projects!
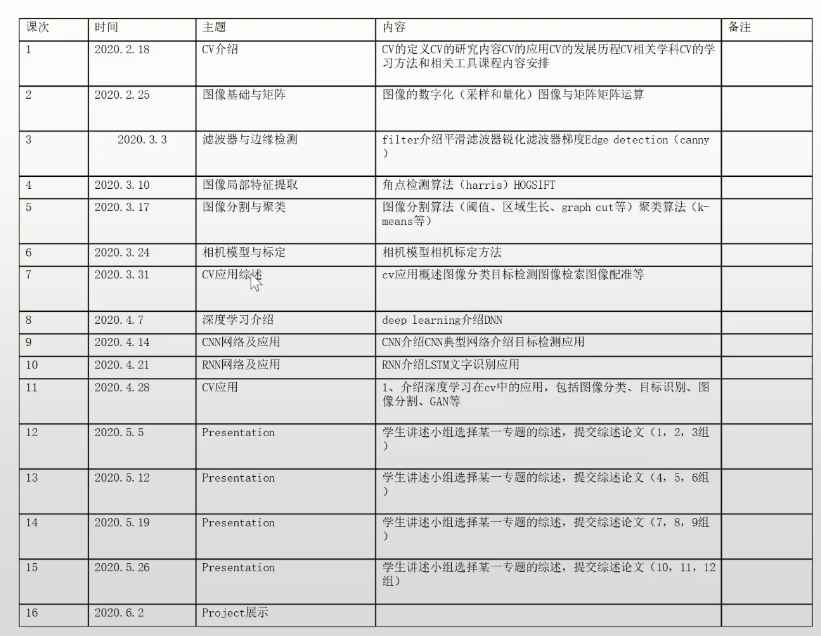
任务
小作业(小组的形式 各自合作共同大项目)
复现一篇相关论文并完成10页的实验报告(类似论文)
1、presentation部分按小组完成一个计算机视觉方向的文献(多篇)阅读,讲解并提交一份文献综述报告;
2、project 每个人完成一个(会下发题目),展示并讲解,提交源代码和实验报告。

所选论文
Learning Efficient Single-stage Pedestrian Detectors by Asymptotic Localization Fitting
源代码:https://github.com/liuwei16/ALFNet
Is Faster R-CNN Doing Well for Pedestrian Detection?
论文链接:https://arxiv.org/abs/1607.07032
源代码:https://github.com/zhangliliang/RPN_BF/tree/RPN-pedestrian
https://github.com/longcw/faster_rcnn_pytorch
https://github.com/CharlesShang/TFFRCNN
参考链接
https://www.cnblogs.com/wangxiaocvpr/p/5747095.html
Is Faster R-CNN Doing Well for Pedestrian Detection?论文阅读
Learning Efficient Single-stage Pedestrian Detectors by Asymptotic Localization Fitting