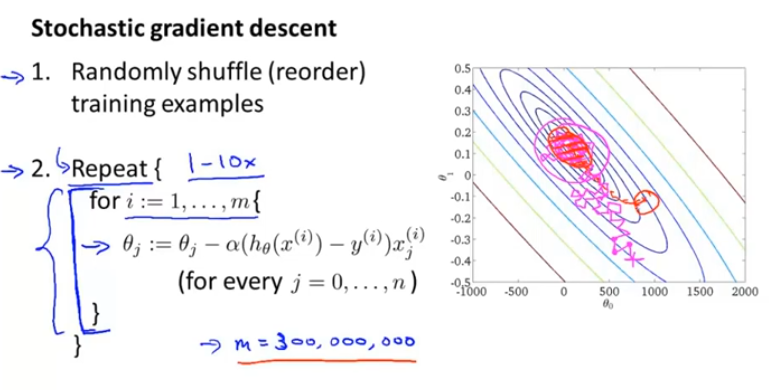
随机梯度下降
打乱数据集顺序,为了收敛更快
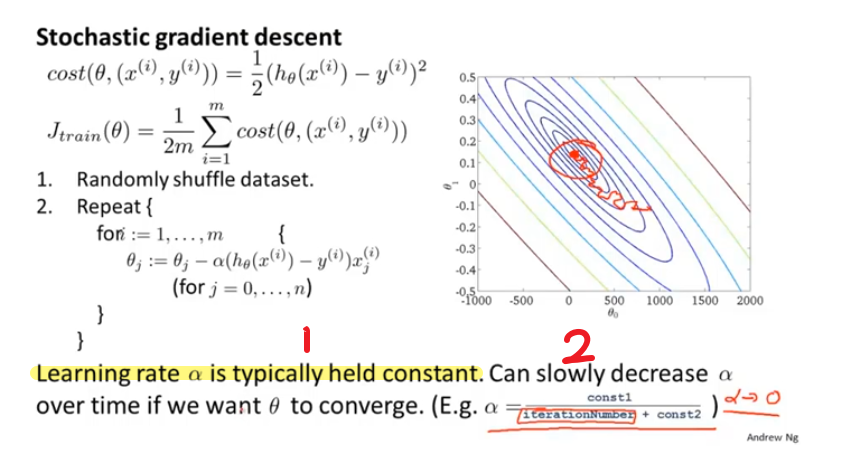
比起批量梯度下降 ,随机梯度下降不需要对整个样本求和后来得到梯度项,可以对单个训练样本求梯度,并且在此过程中已经开始优化参数了。在某个区域连续朝着全局最小值的方向徘徊,而不是像批量梯度下降一样直接达到全局最小值
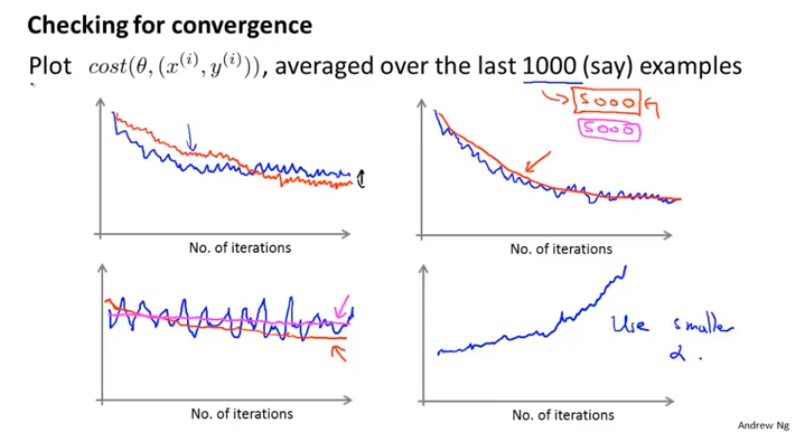
保证收敛以及学习效率α的选择

提前计算 J ,取1000 / 5000样本的均值
红线是α小的曲线
当曲线发散时,可以减小α
当曲线震荡时,可以加大 J 样本数量
假设拥有一个连续的数据不再使用一个固定的数据集,随机梯度下降可以运用于在线学习
Mini-Batch梯度下降(微型梯度下降)
在向量化过程中,Mini-Batch梯度下降可能比随机梯度下降速度、效果更优
缺点是需要确定 b 的大小。


改变学习效率
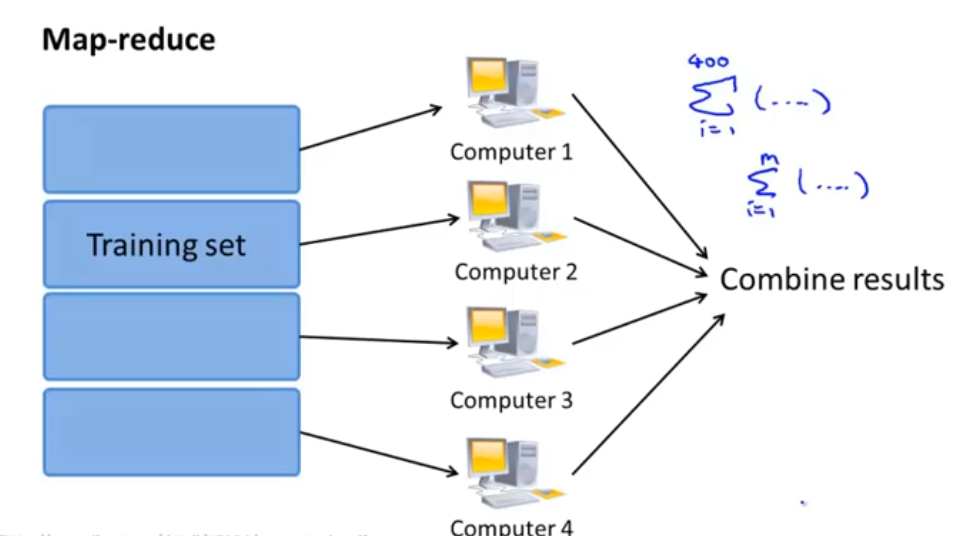
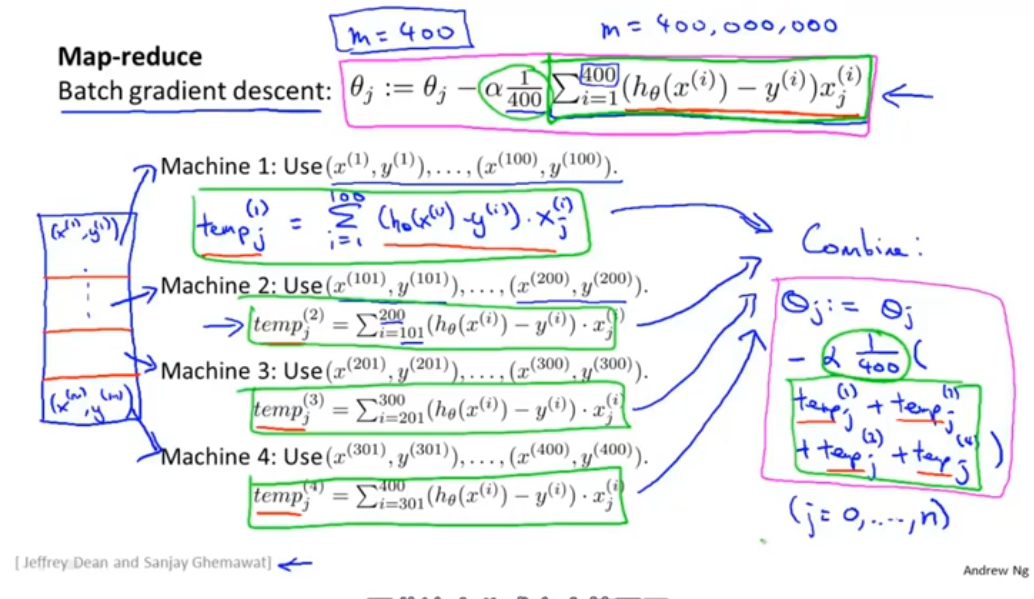
减少映射与数据并行
只要是表示对训练集的求和,便可以用MapReduce 适应于多台计算机和多核电脑