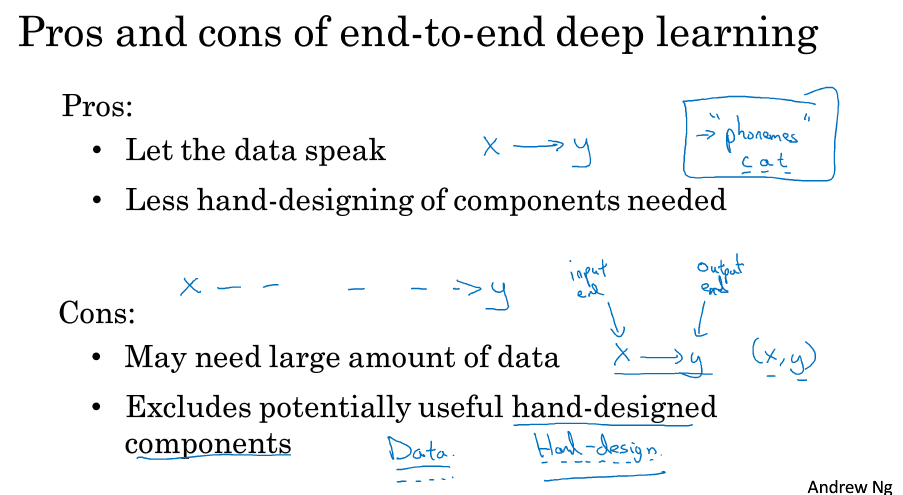
深度学习的含义
深度学习时所指的”深度”是层与层之间更深层次的协调以及随之产生的更加复杂的连接。最终的结果就是你的模型中,有百万级别甚至十亿级别数量的神经元。这就是为什么通过深度神经网络得到的结果。能够极大地优于,早期的手工构建并且手工调试的模型。
作者:大腿君
链接:https://zhuanlan.zhihu.com/p/32225723
来源:知乎
symbol
层数大于3 (tips:不计输入层)
n^[ l ] : 每层的单元数
a^[ l ] : 每层的激活函数 —- a^[0]为X , a^[l]为y^
w^[ l ] : 在 a^[ l ]中计算z^[ l ]的权重
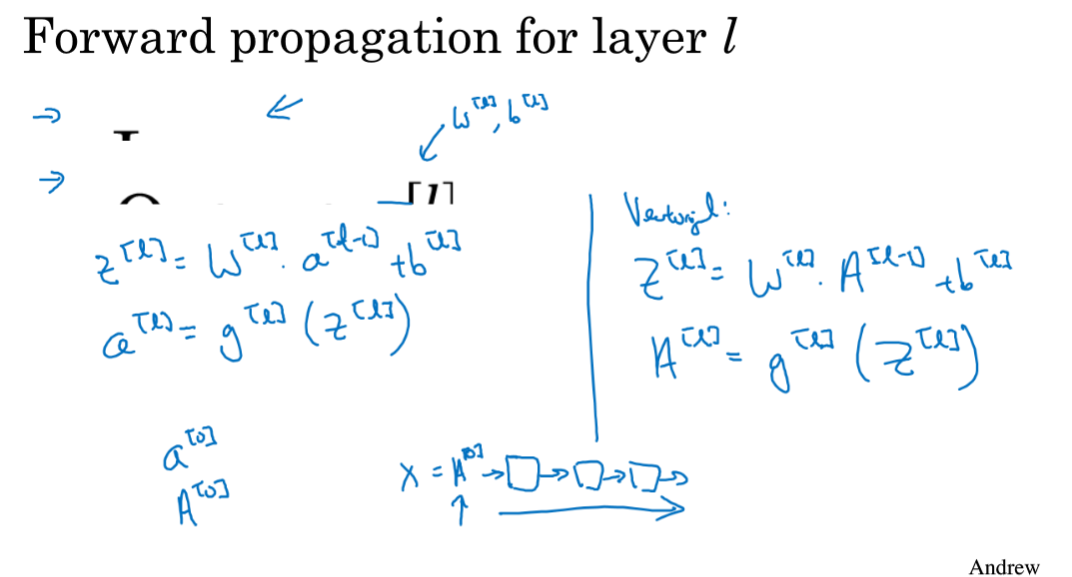
深层神经网络的前向和反向传播
( 深度神经网络版梯度下降法正反向传播 )
前向传播似乎没有比“显示for循环”更好的办法
z^[i] = w^[i] * a^[i-1] + b^[i]
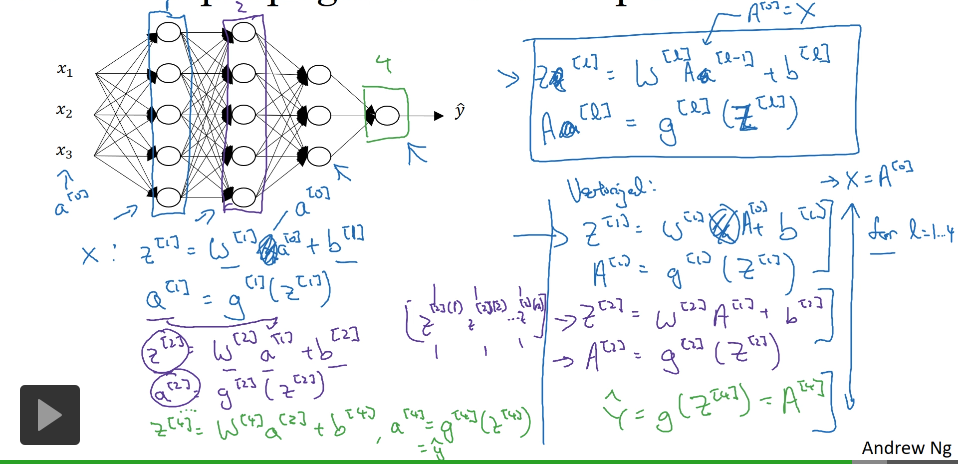
检查bug :过一遍生成矩阵的维数
z^[i] 的维数 = [ n^[i] ,1 ] = b^[i] 的维数
w^[i] 的维数 = [ n^[i] , n^[i-1] ]
反向传播 中 dw^[i] 的维数等于 w^[i]
db^[i] 的维数等于 b^[i]
向量化实现
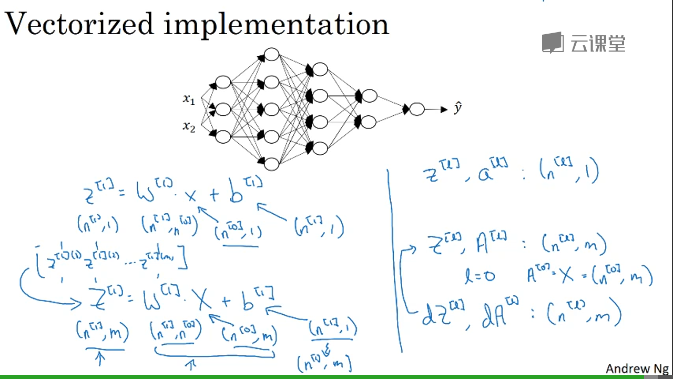
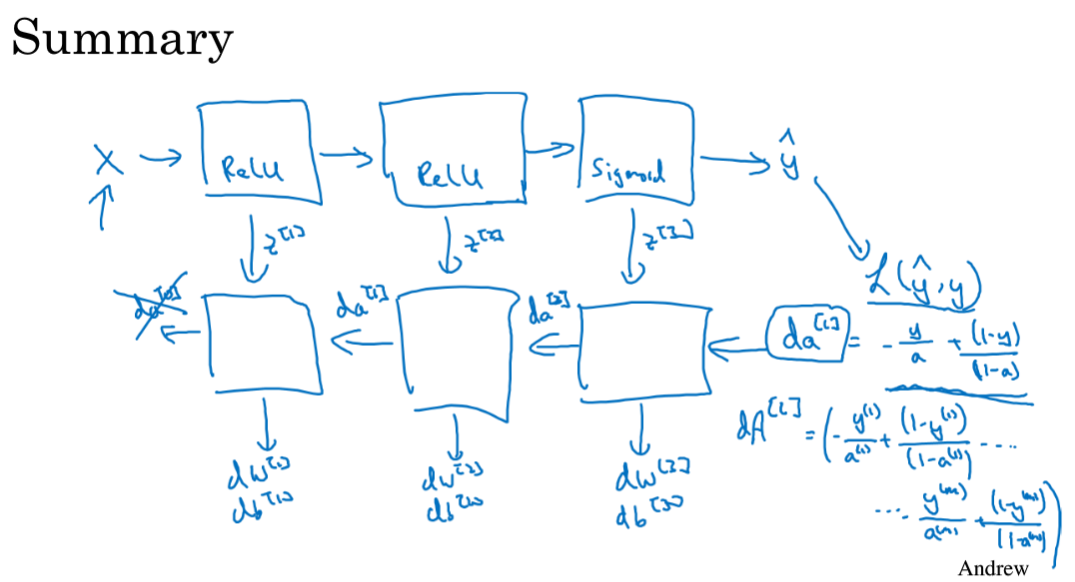
搭建神经网络块
缓存 z
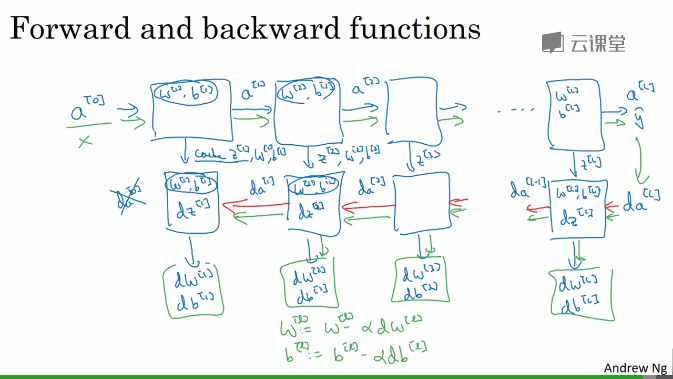
向量化实现

参数与超参数
超参数 最终决定了 h(x)中参数的值
目前根据数据或者经验来不断调试超参数的值
方差 与 偏差
偏差 bias 👆 训练集错误率 👆 欠拟合
方差 variance 👆 交叉验证集错误率 👆 过拟合
Dropout 正则化
设置神经网络中每个节点消除或保留的概率,随机消除节点,从而得到节点更少,规模更小的网络
dropout 会压缩权重并完成一些预防过拟合的外层正则化,可能更适用于不同的输入范围。
keep-prob 代表每一层上保留单元的概率

梯度爆炸与梯度消失
举例 : 如果 激活函数是线性的,与神经网络层数有关的话,呈指数级关系,容易出现梯度爆炸或消失
通过初始化神经网络的权重来部分解决
采用双边误差的方法来检测梯度的数值逼近

梯度检测
检查反向传播是否出错

注意事项:
mini-batch梯度下降
在面对大型的训练集时,将训练集分为几个 大小一致 的集合依次训练
对比随机梯度下降、batch梯度下降、mini-batch梯度下降
batch梯度下降:代价函数从某处值开始向最小值收敛,步长大一些。但在训练集巨大时,单次迭代耗时巨大。
随机梯度下降:随机取点,只对一个样本进行梯度下降,大部分向着全局最小值靠近,小部分方向错误,最终在
最小值附近徘徊,但始终不会收敛。但丧失向量化速度优势
修改mini-batch的size,可以在随机梯度下降与batch梯度下降中转换

如何针对实际情况选择size
如果训练集较小(m < 2000), 使用 batch梯度下降
如果训练集较大, 使用 随机梯度下降
一般的mini-batch size :64 ,128, 256 ,512 适应计算机存储方式
指数加权平均
以伦敦每日气温为例, 预测曲线的点与前一天、今天的温度有关
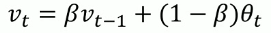
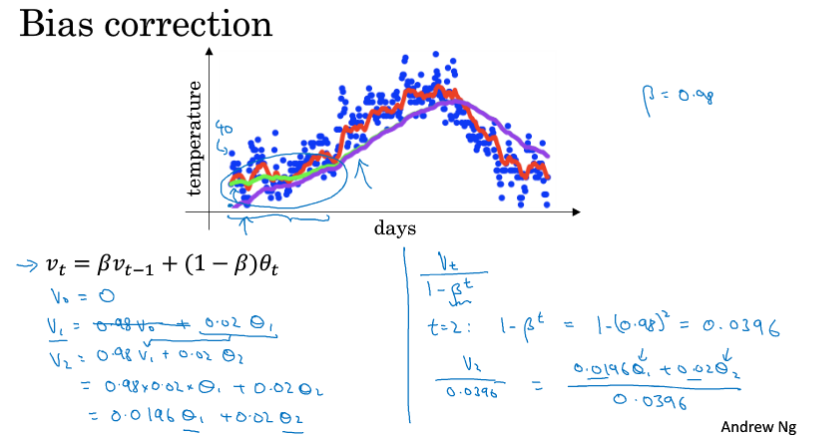
偏差修正
紫色初始端路线变为绿色曲线
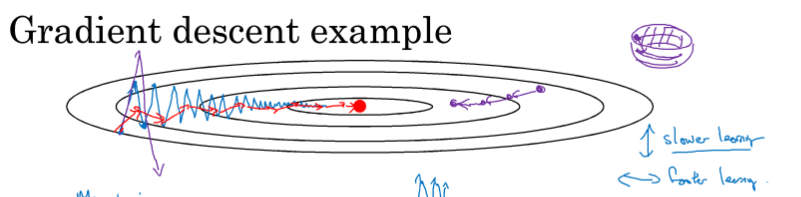
梯度下降消除摆动算法
动量梯度下降
在某些情况下希望梯度下降在上下方向缓慢一些,在左右方向快速一些

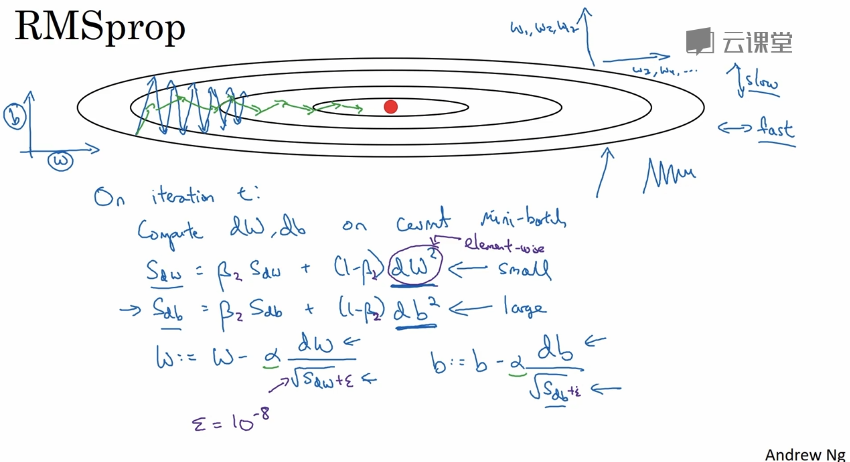
RMSprop
root mean square prop算法也用来加速梯度下降,消除梯度下降中的摆动。
Adam
adaptive moment esimation 算法是以上两种算法的结合版

一般情况下只需调整alpha的值,其他缺省
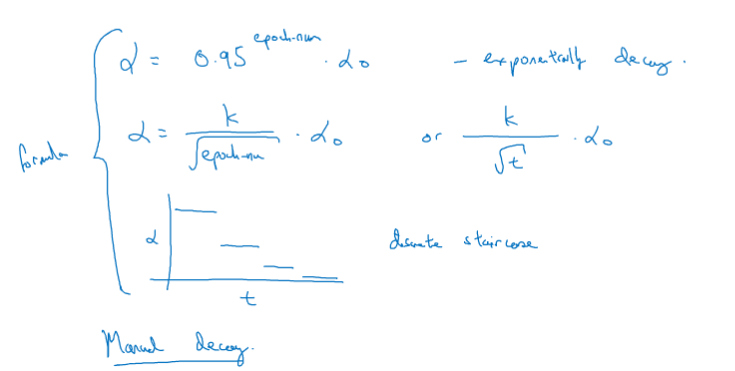
学习率衰减
加快学习网络效率,随着时间慢慢减少学习率
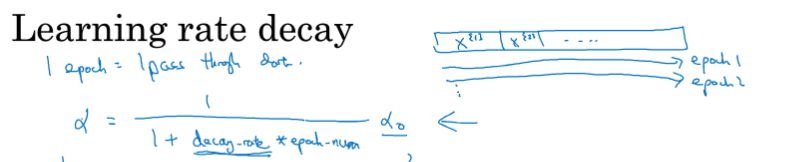
局部最优问题
因为训练了一个大型的神经网络,所以不太可能陷入一个糟糕的局部最优中
平稳区会降低学习速率
超参数调试方法
(1)使用随机值,而非网格,来明确哪些超参数比较重要
(2)由粗到细,放大 效果较好的点集,更密集地随机取点
(3)选择合适的超参数取值范围
(4)β (指数加权平均参数)不适合线性轴均匀取值,再接近某个值时对结果影响巨大。
“熊猫模式” 与 “鱼子酱模式 ”
随着时间,根据数据的变化改变超参数的值;
同时并行多个模型,挑选适应性较好的模型;
正则化网络的激活函数
归一化输入(输入层、隐藏层)来加快学习速率
Batch Norm 归一化 发生在 z与a之间,激活函数前
它减弱了前一层参数的作用与后一层参数的作用之间的联系,使得结构更稳定

在测试阶段的 batch norm 需要逐一处理样本 根据训练集估算 μ和σ^2
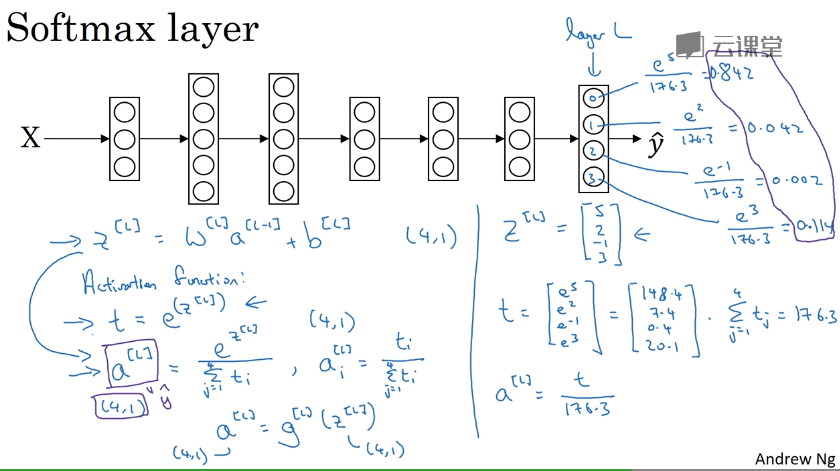
Softmax 回归
将逻辑回归激活函数推广到了多类即:多个输入值而不是0、1了
深度学习框架
TensorFlow

数据集划分
在机器学习领域大多是
| 训练集 | 交叉验证集 | 测试集 |
|---|---|---|
| 70% | 30% | |
| 60% | 20% | 20% |
而在深度学习领域
| 训练集 | 交叉验证集 | 测试集 |
|---|---|---|
| 98% | 1% | 1% |
因为深度学习比较吃数据,而且数据集比机器学习所需要的大多了

误差分析
在结果中找寻错误例子,观察错误标记的例子,对每种错误进行分类,看看真阳性或假阴性。统计不同种错误类型的占比,分析改善后其性能上限。
深度学习对随机误差有很强的鲁棒性
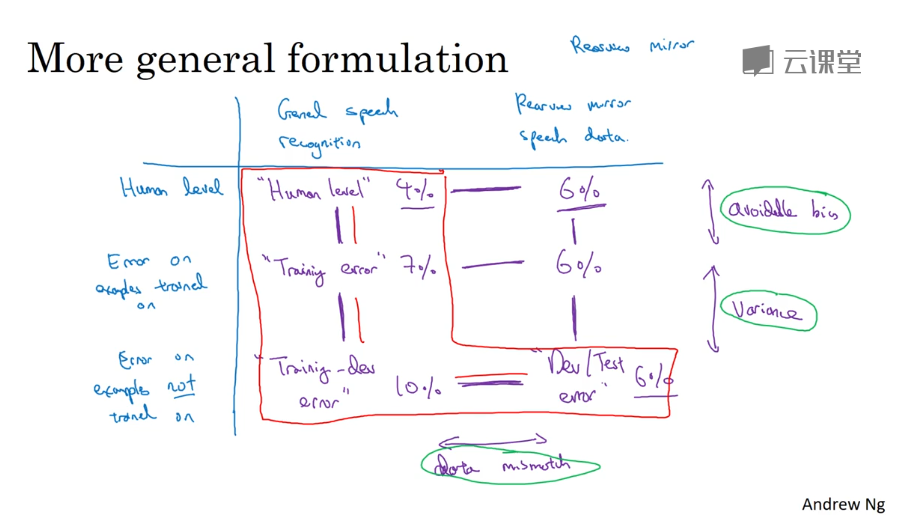
训练集和验证集、测试集要来自同一分布
可避免偏差 :训练集分类错误率 与 人类分类错误率之间的差距
方差 :训练集分类错误率 与 traning-dev(或测试集)分类错误率之间的差距
数据不匹配:有时可人工制造数据,但要注意过拟合问题
迁移学习
试图优化数据相对较少的任务B,寻找一个相关但不同的任务A(数据量较大)训练得到低层次的特征,改善B的学习情况
何时迁移才起作用:

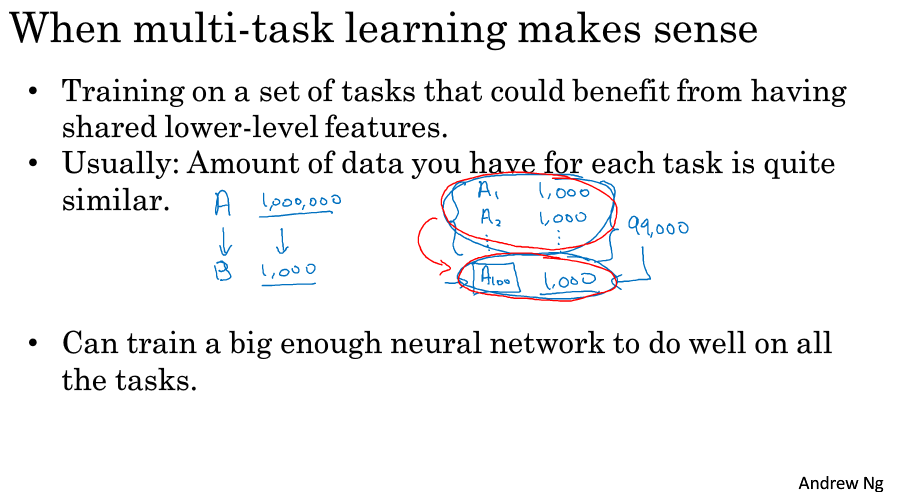
多任务学习
单神经网络同时解决多个问题,(比如 对图片标注多个标签)
在数据量较大的情况下,多任务学习性能较好
代替方式:为每一个问题训练单神经网络
何时“多任务学习”才起作用:
端到端学习
需要大数据集才能表现其优点