三维重建
定义
根据单视图或者多视图的图像重建三维信息的过程
研究意义
港科大教授权龙认为:
真正意义上的计算机视觉要超越识别,感知三维环境。
三维重建将作为计算机视觉的核心。将识别与重建融为一体,实现实时、精确的场景模型重构以及环境感知。作为环境感知的关键技术之一,可用于自动驾驶、虚拟现实、运动目标监测、行为分析、安防监控和重点人群监护等。
实现手段
根据,分为两类:基于主动视觉理论和基于被动视觉的三维重建方法。
主动视觉三维重建方法:主要包括结构光法和激光扫描法。
被动视觉三维重建方法:被动视觉只使用摄像机采集三维场景得到其投影的二维图像,根据图像的纹理分布等信息恢复深度信息,进而实现三维重建。
根据,分为四种:深度图(depth)、点云(point cloud)、体素(voxel)、网格(mesh)
深度图(depth): 图中每个像素值代表的是物体到相机xy平面的距离,单位为 mm。
点云(point cloud):某个坐标系下的点的数据集。点包含了丰富的信息,包括三维坐标X,Y,Z、颜色、分类值、强度值、时间等等。在我看来点云可以将现实世界原子化,通过高精度的点云数据可以还原现实世界。万物皆点云,获取方式可通过三维激光扫描等。
体素(voxel):三维空间中的一个有大小的点,一个小方块,相当于是三维空间种的像素。
网格(mesh):由三角形组成的多边形网格。多边形和三角网格在图形学和建模中广泛使用,用来模拟复杂物体的表面,如建筑、车辆、人体,当然还有茶壶等。任意多边形网格都能转换成三角网格。
缺点:
从单张图片恢复出三维物体形状这一研究课题在许多应用中扮演着重要的角色,例如增加现实,图像编辑。但是由于物体的拓扑结构复杂多变,这一课题也颇具挑战性。目前,基于体素表达的方法受限于三维卷积网络计算和内存的限制而难以得到高分辨率的输出。基于点云表达的方法又很难生成平滑而又干净的表面。
三角网格表达对物体形状提供了一种更有效,更自然的离散化逼近方式,但是计算复杂。
( volume受到分辨率和表达能力的限制,会缺乏很多细节;point cloud 的点之间没有连接关系,会缺乏物体的表面信息。相比较而言mesh的表示方法具有轻量、形状细节丰富的特点。 )
这些方法本质上是在对一个给定拓扑连接关系的初始网格变形,比较有代表性的初始网格有单位平面,球。尽管它们有一定的效果,但是仍然难以恢复具有复杂拓扑结构的物体表面,
未来趋势
将三者方式结合起来,从单张RGB图片中识别多个物体,并重建三维模型。
文献
2017
A Point Set Generation Network for3D Object Reconstruction from a Single Image
作者:Haoqiang Fan(Tsinghua University),
Hao Su, Leonidas Guibas(Stanford University)
来源:CVPR 2017 (oral)
文章链接:https://arxiv.org/abs/1612.00603
源码链接:https://github.com/fanhqme/PointSetGeneration
方法:
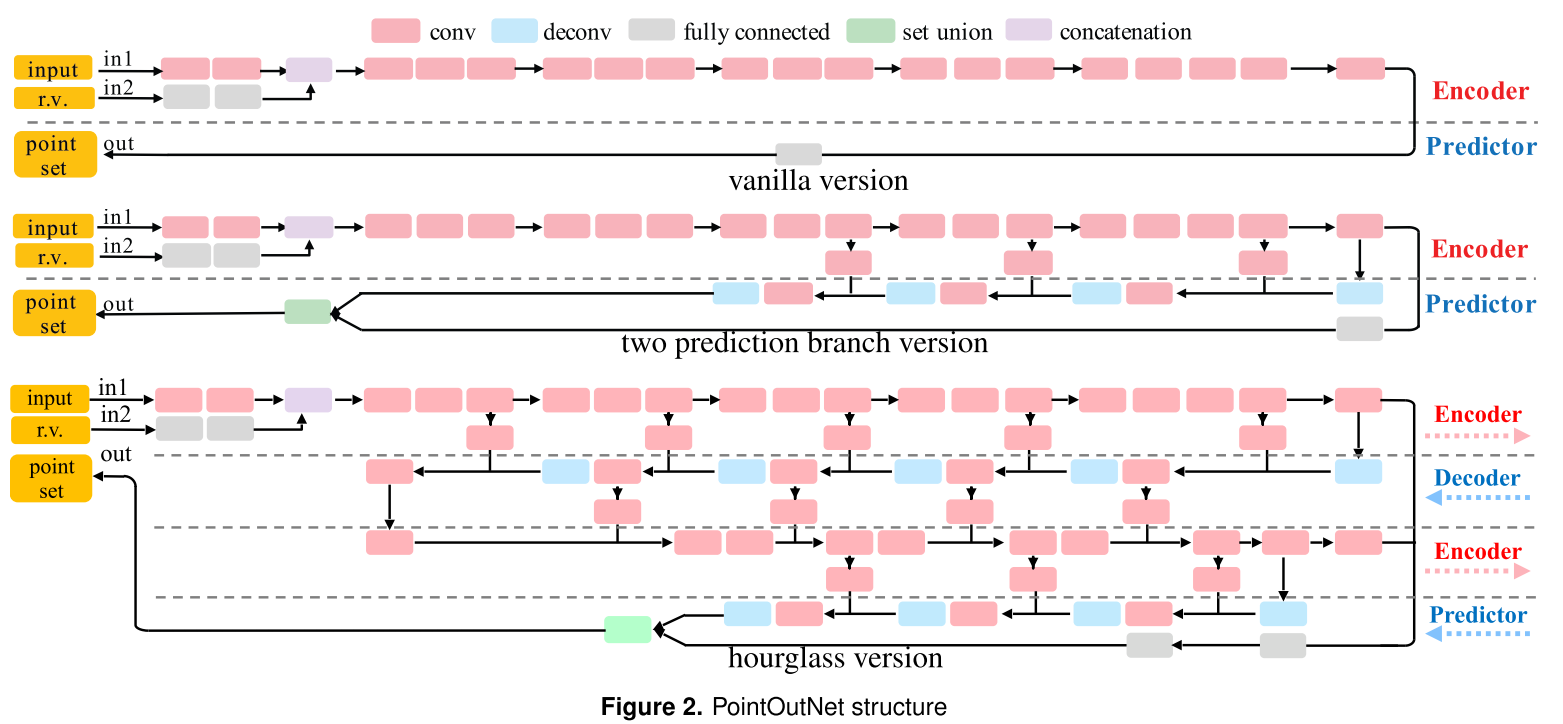
网络分为3个版本,输入都为二维图像I和一个用来使系统产生分布式输出的随机向量r,输出为N * 3的矩阵M。
- vanilla version
vanilla version分为Encoder(编码器)和Predictor(预测器),Encoder由卷积层和ReLU层组成,随机向量r干扰了图像I的预测,Predictor由全连接网络生成N个点的坐标。 - two prediction branch version
该网络由vanilla改进而来,在vanilla的基础上在预测器中加入了deconv(反卷积),由于全连接网络对复杂结构表现出良好的性能,但对于简单光滑的结构便显得有些繁重,故引入deconv结构来优化网络,使得参数变少,并且这种结构对光滑表面效果很好。
tips:其中添加了多个编码器和预测器之间的链接,以促进编码和预测之间的信息流。 - hourglass version
沙漏版本在前一个版本的基础上增加了递归循环,能更好的进行编解码操作,具有较强的表示能力,能较好的融合全局和局部信息。
损失函数:
Chamfer distance (倒角距离 ) 在另一个集合中找到最近的点,并将其距离的平方求和。(并不是距离公式,因为它不满足三角形不等式)其特点是能更好的保存物体的详细形状
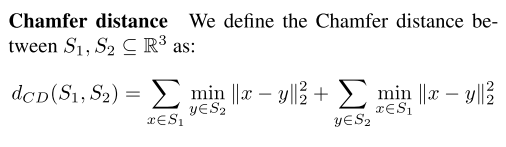
Earth Mover`s distance (EMD距离) 测量两个分布之间的距离,能产生相较于CD算法更紧凑的结果,但有时会过度收缩局部结构

结果:
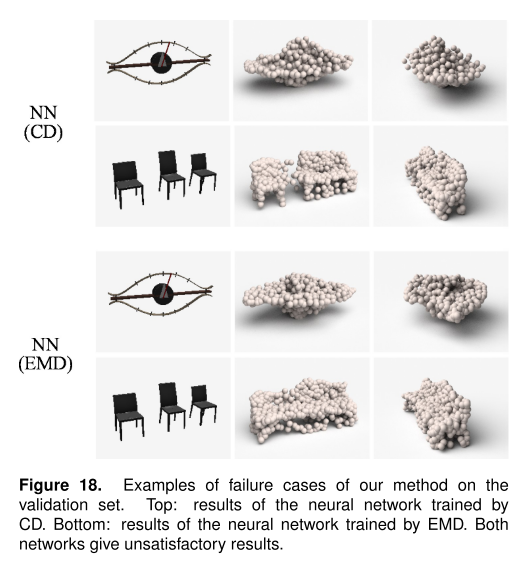
成功的重建

失败的重建
贡献:
(1)开创了单个2D视角用点云重构3D物体的先例(单图像3D重建)
(2)系统地探讨了体系结构中的问题点生成网络的损失函数设计
(3)提出了一种基于单图像任务的三维重建的原理及公式和解决方案
(4)将输入改为RGBD图像,能够更加弥补原先模型缺失的部分
缺点:
(1) 对于一部分与训练数据存在一定偏差的输入,该网络会用类似的东西来解释输入。
(2) 对于多个对象的组合,因没有实现检测或注意机制,导致输出失真。
2019
(重点看)A Skeleton-bridged Deep Learning Approach for Generating Meshes of Complex Topologies from Single RGB Images
作者: Jiapeng Tang, Xiaoguang Han , Junyi Pan, Kui Jia y, Xin Tong
School of Electronic and Information Engineering, South China University of Technology Shenzhen Research Institute of Big Data, the Chinese University of Hong Kong (Shenzhen) Microsoft Research Asia
来源:CVPR 2019(oral)
文章链接:https://arxiv.org/abs/1903.04704?context=cs.CV
源码链接:暂无
方法:
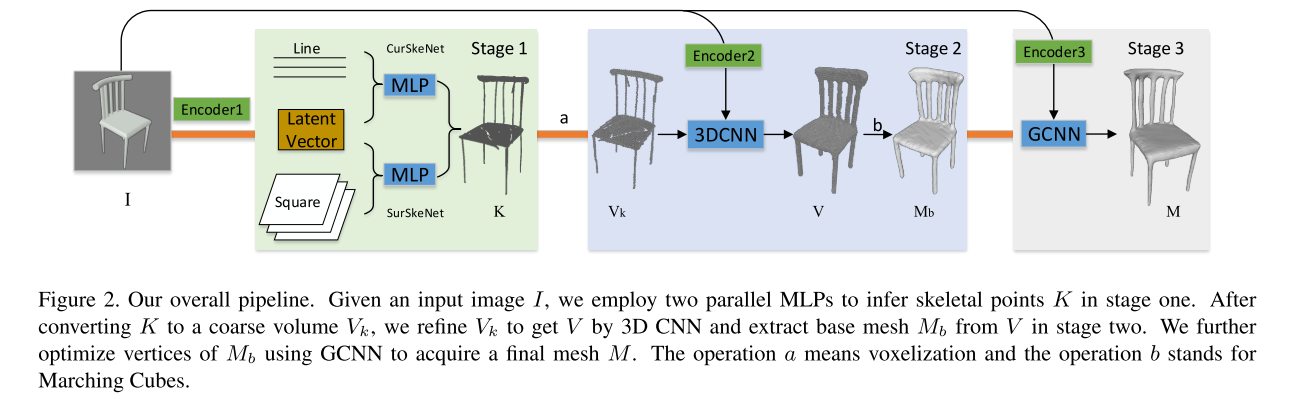
第一阶段是从输入图像中学习生成骨架点云。为此他们设计了平行的双分支网络架构,被命名为 CurSkeNet 和 SurSkeNet,分别用于曲线状和曲面状骨架点云的合成。为了 CurSkeNet 和 SurSkeNet 的训练,他们针对 ShapeNet 的物体模型处理了骨架数据集来当做 ground truth 用于训练。 他们采用编码器-解码器的网络结构从输入图片 I 学习出对应的骨架 K,它本质上是一个更简洁紧凑的点云表达。
在第二个阶段,他们通过将合成的骨架点云体素化,然后用三维卷积网络对粗糙的骨架体素进行修复提取出一个初始网格。此处为了减小高清体素输出时的网络复杂度,采取了用全局结构引导分块体素修复的方式,得到一个更精细化的体素 V。
最后一个阶段先从体素 M 中提取出一个粗糙的初始网格 Mb,然后再用图神经网络对网格的顶点位置进一步优化,得到最后的输出网格 M。
每个阶段都有一个图像编码器-解码器来提取所各自需要的信息
结果:

贡献:
- 提出了阶段性学习的方法,利用了点云,体积和网格各自的优点,而且对有孔洞的物体又能够很好地重建
- 骨架桥接的方法
- 腐蚀学习方法来验证算法功效
缺点:
- 在多次训练后,仍然会在连接处、角落等缺失,或许添加深度图信息会有所改善
- 模型过于复杂
- 所展示的模型只是简单场景中的单个物体,而且最终轮廓比较圆润,没有线条感
Mesh R-CNN
作者: Georgia Gkioxari、 Jitendra Malik、 Justin Johnson
Facebook AI Research (FAIR)
来源:CVPR 2019(oral)
文章链接:https://www.researchgate.net/publication/333650113_Mesh_R-CNN
源码链接:暂无
方法:
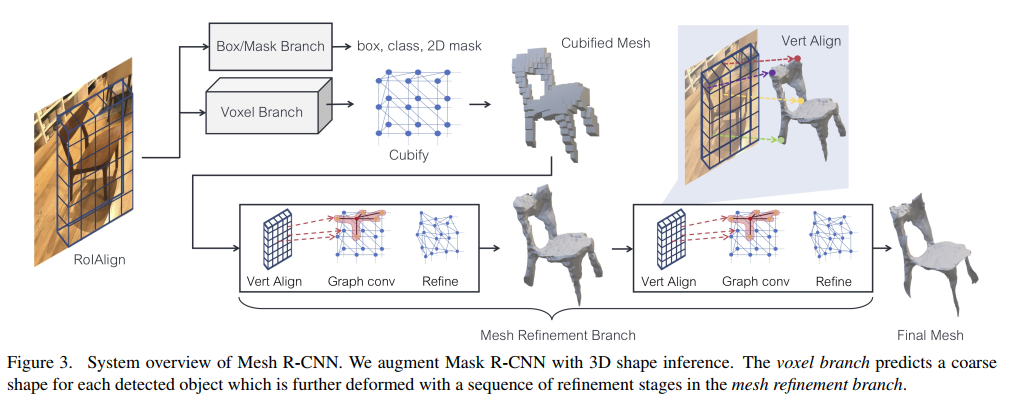
基于Mask R-CNN(论文链接、源码链接, 在进行目标检测的同时进行实例分割 )改进而来,增加了网格预测分支来输出高分辨的目标三角网格。 通过先预测转化为物体的粗体素分布并转化为三角形网格表示,然后通过一系列的图卷积神经网络改进网格的边角输出具有不同拓扑结构的网格。
结果:

贡献:
- 开发了从2D感知到3D形状预测的方法( 图卷积神经网络 )
- 由粗到细调整的思想
- 目标3D三角网格预测,有效地预测带有孔洞的物体 ,同时对于复杂环境中的三维物体也有良好的预测效果。
缺点:
- 细节缺失较为严重,如上图的凳腿,椅背
- 重构的模型看起来比较粗糙,没有线条感(作者解释说缺乏大量的真实场景数据-监督)