1 论文介绍
1.1 方法概述
该论文提出了一种将单张RGBD图像转换为多视角合成的3D照片的方法,给定上下文区域和现有RGB-D信息,来预测(修补)合成区域颜色值和深度值。
预处理阶段:给定输入的 RGB-D 图像(深度图除了来自双摄像头的不同视角,或者深度相机,或者用普通的RGB图通过DPSNet估计出来),首先将输入的 RGB-D 图的深度通道归一化到 0-1 之间,如图1.1(a-b)所示。并对深度图进行双边中值滤波来锐化以使得边缘更细化,如图1.1(c-d)所示。再基于此图片生成初始 LDI(Layered Depth Image)。然后再根据给定阈值(论文中定义为10 )判断相邻像素的视差,找到深度不连续像素,最后删除短的不连续边(包括孤立的和悬空的片段,size<10像素),得到最终的深度不连续边集合,如图1.1(e-f)所示。
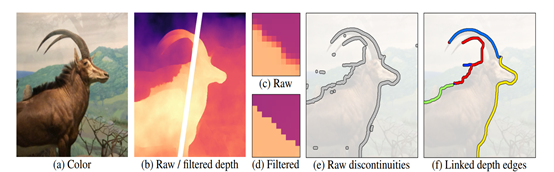
图1.1 预处理步骤图
分割阶段:每次选择一条深度不连续边借助填补算法来修复背景,首先在深度不连续处断开 LDI 像素连接,得到 (前景、背景) 轮廓像素,如图1.2(b)所示。合成区域就在背景轮廓附近,如图1.2(c)所示红色区域所需要修复的部分。“联系上下文”,根据背景轮廓周围的像素来推测红色块原本隐藏的部分。使用分水岭算法初始化颜色和深度值,再使用深度学习的方法填补该合成区域。由于检测到的深度边缘在遮挡边界附近可能没有很好的对齐,所以将合成区域扩大了5个像素。这种策略有助于减少合成区域中的artifacts。
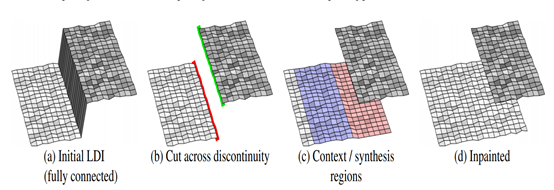
图1.2 分割图
修复阶段:给定颜色、深度、提取以及连接的深度边缘作为输入,随机选择其中一个边作为子问题。首先使用边缘修复网络修复合成区域中(红色区域)的深度边缘,然后将修复后的深度边缘与语境颜色连接在一起,并应用颜色修复网络生成用以修复的颜色。类似地,将修复后的深度边缘与语境深度连接起来,并应用深度修复网络生成修复深度。
多层修复阶段:在deep-complex的情况下,使用一次inpainting模型的效果是不完美的,因为inpainting深度边缘不连续区域过程中仍会出现空白(hole),如图1.3(b)所示。因此,多次应用inpainting模型,直到没有进一步的inpainted深度边缘生成,可彻底消除这些artifacts,如图1.3(c)所示。

图1.3 多次修复效果图
合成阶段:通过将所有修复好的颜色和深度值重新集成到原始 LDI 中,形成最终的 3D 纹理网格。使用网格表示可以快速渲染新的视图,而无需对每个视角进行推理,因此文章算法得到的3D表示可以在边缘设备上通过标准图形引擎轻松渲染。
1.2 网络架构
论文中的网络架构如图2.1,将整个修补工作由三个子网络组成,分别是边缘修复网络、颜色修复网络、深度修复网络。
(1)将上下文区域的边作为输入,使用边修复网络预测合成区域中的深度边,先预测边信息能够推断 (基于边的) 结构信息,有助于约束 (颜色和深度的) 内容 预测。
(2)再以边缘修复网络提供的物体结构信息和上下文区域的颜色,使用颜色修复网络预测合成区域中的颜色。
(3)最后再使用同样的方法预测合成区域中的深度信息。
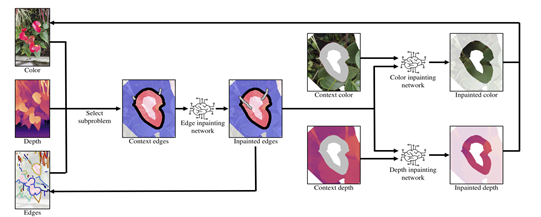
图2.1 网络架构
边缘修复模型由一个边缘生成器和一个鉴别器网络组成。SN→IN表示先进行光谱归一化(SN),再进行实例归一化(IN)。ResnetBlock由2个卷积层、指定的超参数和一个block输入和输出之间的跳跃连接组成。
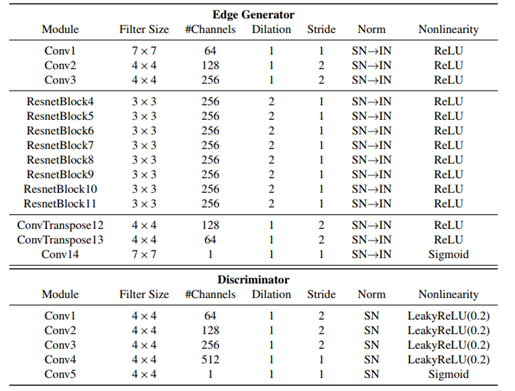
而深度和颜色的渲染网络由一个标准的U-Net架构和部分卷积层构成。其中,下图内PConv表示部分卷积层, BatchNorm表示BN。我们添加上下文和合成区域作为PConv层的局部掩码。
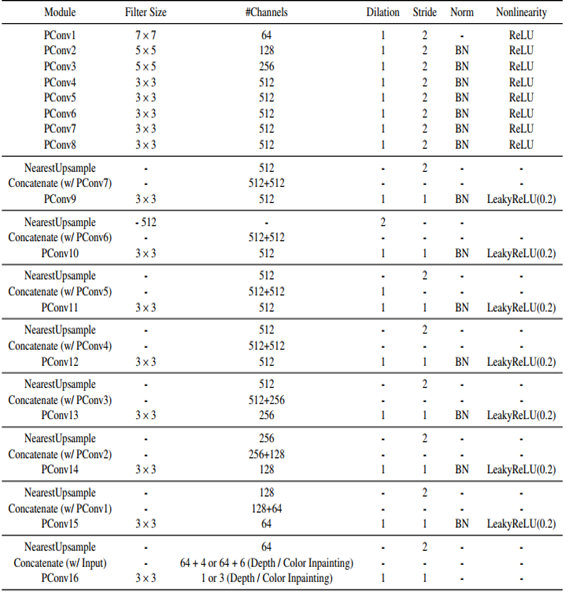
将三个模型的合成区域的输入深度和RGB值设置为0。对于深度和颜色的修复模型,合成区域的输入边缘值同样被设为0,而对于边缘修复网络,则保持不变。
1.3 项目说明
main.py:执行3D照片修复
mesh.py:关于上下文感知深度的函数
mesh_tools.py:在mesh.py中使用的一些常见函数
utils.py:一些用于图像预处理,数据加载的常用函数
networks.py:修复模型的网络架构
ImageRename.py:按0000xx.png的格式重命名RealEstate10K数据集图片
Image文件夹保存实验数据(随机挑选10张样例作演示)
Video文件夹保存生成的3D视频(只放入样例,理由如上)
MiDaS 文件夹下
run.py:执行深度估计
monodepth_net.py:深度估计模型的网络结构
MiDaS_utils.py:深度估计中的一些常见函数
相关环境
- Linux ( Ubuntu 18.04.4 LTS)
- Miniconda
- Python 3.7.7
- PyTorch 1.5.0
- 其他的 Python 依赖项:
1 | opencv-python==4.2.0.32 |
安装
- 运行以下指令开始安装:
1 | 已有现成的pytorch环境,可跳过 |
其中安装 cynetworkx报错
ModuleNotFoundError: No module named ‘Cython’
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
ModuleNotFoundError: No module named ‘decorator’
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
1 | cynetworkx是networkx包的cython端口,用于创建、操作和 复杂网络的结构、动力学和功能的研究 |
下载模型权值:
1
2
3+x 是添加执行文件权限
chmod +x download.sh
./download.sh
运行示例
1 | python main.py --config argument.yml |
3D照片的生成将需要2-3分钟,将取决于可获得的计算资源
如果想改变默认配置。请阅读document .md并修改argument.yml 。
实验
需要tizifanguoqu下载
https://raw.githubusercontent.com/richzhang/PerceptualSimilarity/master/models/weights/v0.1/alex.pth
一般实验均包括以下三个方面:
量化实验(与其他的方法做对比)
Ablation study 消融实验(网络各个组件进行对比,那一部分贡献最大)
可视化结果
经过以上实验后,该模型在日常的大部分场景图片中都能够生成效果炫酷、惊艳的3D照片,该论文方法在SSIM和PSNR上都有较好的性能,其优越的LPIPS评分表现出更好的感知质量。但仍然存在下面三个缺点:
对于复杂或者稀疏结构的场景(如4.3节中的路灯),不能得到满意的结果。
该论文模型不能很好地处理反光/透明表面(如4.3节中的透明花瓶)
生成时间过长,通常情况下在本人电脑上处理时间为 4-6 分钟,具体取决于可用的计算资源。
本人认为导致这些结果的原因有四个:
应该是现有的单图像深度估计算法(如MegaDepth)通常难以处理稀疏和复杂的结构,并可能产生过于平滑的深度地图。
由于使用了显式深度映射,RGB颜色信息与深度信息需要进行一些处理操作来对齐。在此过程中,深度信息损失过多。
从单一的一张图片生成多个视角的视频序列所能利用的信息量太少,导致生成结果细节丢失严重,补充不到位。
模型过于复杂,当遇到深度不连续边数量过多时,需要多次迭代才能完成。