强化学习基本概念
强化学习被认为是实现人工智能的通用框架
强化学习使得机器人具备在环境中自主动作的能力
每个动作都能影响机器人在环境中的状态
动作的好坏由状态对应的激励信号决定
累计激励: 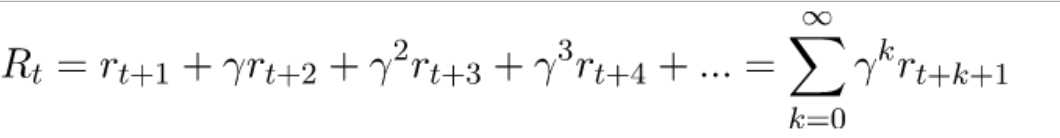
目标:学习选择动作的策略使得将来的累计激励最大化
监督学习与强化学习
监督学习
目标 f(x->y)
x:数据 y:预测目标
存在y的标注信息且y对x无影响
强化学习
目标 π(s->a)
s:状态 a:动作
不存在a的标注信息且a对s有影响
V、Q函数
V函数衡量了机器人在状态s期望获得的累计激励
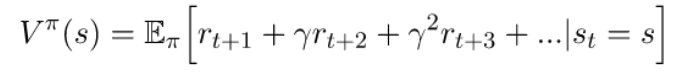
Q函数衡量了机器人在状态s采取动作a之后期望获得的累计激励
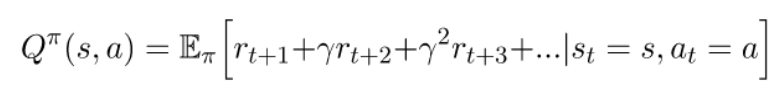
Policy函数
Policy函数代表某种选择动作的策略π(s),或条件概率分布π(a|s),负责根据状态s选择最优的动作a
a=π(s)
基于Q函数的策略:
• 选择动作使得累计激励的期望最大
π*(s) = argmaxQ(s,a)
强化学习的主要模式
Value-based RL(基于价值的)
学习Q函数Q(s,a)
选择使Q函数取最大值的动作
Policy-based RL(基于策略的)
学习Policy函数π(a|s)
从Policy函数采样动作
贝尔曼方程

Q函数的递归关系
采用贝尔曼方程
【缺图】
基于Q函数的强化学习的弊端
复杂性方面:
• 只能对简单离散的动作空间进行建模
• 无法应对连续的动作空间(例如:方向盘的转动角度)
灵活性方面:
• 选择动作的策略Policy由Q函数直接决定(硬策略)
• 无法对策略的随机性进行建模
深层策略网络
Deep Q-Network: 先学习Q函数,然后估计最佳策略
Policy Gradient: 直接学习最佳策略
训练过程:
- 基于当前策略运行一段时间(直至产生激励)
- 若为高激励,则增加选择当前动作的概率
- 若为低激励,则降低选择当前动作的概率
模拟学习
基于带标签的数据训练策略网络
优点:网络收敛快
缺点:探索能力不足,容易过拟合
反(逆向)强化学习
强化学习:激励函数已知
反强化学习:激励函数未知,结合专家示例进行学习(与对抗学习GAN存在本质关联)
策略对应生成器
激励对应鉴别器